 Impulsse.la Complete News World
Impulsse.la Complete News World

IA cuántica de Google
Hoy, Google anunció una demostración de corrección de errores cuánticos de su procesador cuántico de próxima generación, Sycamore. La repetición de Sycamore no es dramática. es la misma cantidad de qubits, solo que con un mejor rendimiento. Y obtener una corrección de error cuántica no es realmente nuevo; pudieron hacerlo funcionar hace unos años.
En cambio, las señales de progreso son un poco más sutiles. En generaciones anteriores de procesadores, los qubits eran tan propensos a errores que agregar más de ellos al circuito de corrección de errores causaba problemas mayores que la adición de correcciones. En esta nueva iteración, es posible agregar más qubits y obtener una tasa de error más baja.
Podemos arreglarlo
La unidad funcional de un procesador cuántico es un qubit, que es cualquier cosa (un átomo, un electrón, una pieza de electrónica superconductora) que se puede usar para almacenar y controlar un estado cuántico. Cuantos más qubits tenga, más capaz será la máquina. Hasta que tenga acceso a unos pocos cientos, se cree que puede realizar cálculos que serían difíciles o imposibles de realizar en el hardware de una computadora tradicional.
Es decir, suponiendo que todos los qubits se comporten correctamente. Cosa que, en general, no hacen. Como resultado, arrojar más qubits a un problema aumenta la probabilidad de que encuentre un error antes de que se complete el cálculo. Así que ahora tenemos computadoras cuánticas con más de 400 qubits, pero intentar hacer cualquier cálculo que requiera los 400 fallará.
La creación de un qubit lógico con corrección de errores se acepta generalmente como una solución a este problema. Este proceso de creación implica la distribución de un estado cuántico entre un conjunto de qubits conectados. (En términos de lógica computacional, todos estos qubits de hardware se pueden abordar como una sola unidad, por lo tanto, un «qubit lógico»). La corrección de errores se habilita mediante qubits adicionales adyacentes a cada miembro del qubit lógico. Estos se pueden medir para averiguar el estado de cada qubit que forma parte de un qubit lógico.
Ahora bien, si uno de los qubits de hardware que forma parte del qubit lógico tiene un error, el hecho de que solo almacene parte de la información del qubit lógico significa que el estado cuántico no está dañado. Y medir a sus vecinos detectará el error y permitirá una pequeña manipulación cuántica para solucionarlo.
Cuantos más qubits de hardware dedique a un qubit lógico, más robusto debería ser. Por el momento solo hay dos problemas. Una es que no tenemos qubits de hardware de sobra. Ejecutar un esquema sólido de corrección de errores en procesadores con la mayor cantidad de qubits nos permitiría considerar usar menos de 10 qubits por cálculo. El segundo problema es que la tasa de error de los qubits de hardware es demasiado alta para que cualquiera de ellos funcione. Agregar qubits existentes a un qubit lógico no lo fortalece; aumenta la posibilidad de cometer tantos errores a la vez que no se pueden corregir.
Lo mismo pero diferente
La respuesta de Google a estos problemas fue crear una nueva generación de su procesador Sycamore, que tenía la misma cantidad y disposición de qubits de hardware que la anterior. Pero la empresa se ha centrado en reducir la tasa de error de los qubits individuales para poder realizar operaciones más complejas sin fallar. Este es el hardware que usa Google para probar los qubits lógicos con corrección de errores.
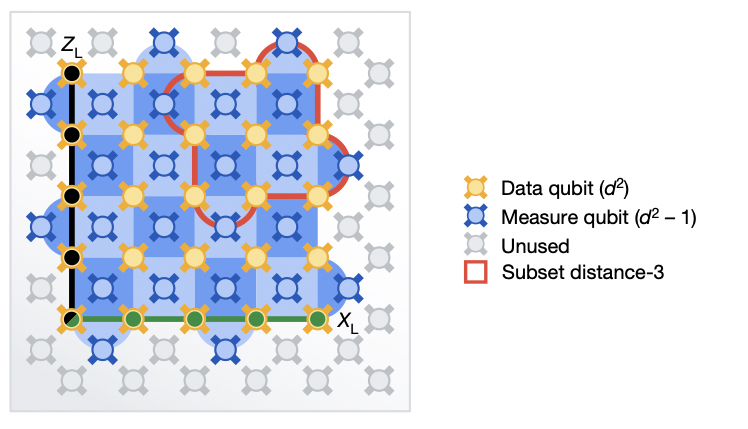
Los dos ajustes de corrección de errores, la versión más pequeña en rojo y la versión más grande en azul. En ambos casos, los qubits de datos y corrección de errores son adyacentes entre sí.
IA cuántica de Google
El documento describe las pruebas de dos métodos diferentes. En ambos, los datos se almacenaron en una cuadrícula cuadrada de qubits. Cada uno de estos tenía qubits vecinos que se midieron para realizar la corrección de errores. La única diferencia era el tamaño de la cuadrícula. En un método, eran tres qubits por tres qubits; en el segundo, cinco eran cinco. El primero requirió un total de 17 qubits de hardware. los últimos 49 qubits, o casi tres veces más.
El equipo de investigación realizó una serie de mediciones de rendimiento. Pero la pregunta principal estaba clara. ¿Qué qubits lógicos tuvieron la tasa de error más baja? Si dominaran los errores en los qubits de hardware, se esperaría que la cantidad de qubits de hardware se triplicara para aumentar la tasa de error. Pero si los ajustes de rendimiento de Google mejoran lo suficiente los qubits de hardware, el diseño más grande y más robusto debería reducir la tasa de error.
El esquema más grande ganó, pero estuvo cerca. En general, el qubit lógico más grande tuvo una tasa de error del 2,914 por ciento, en comparación con el 3,028 por ciento del más pequeño. No es una gran ventaja, pero es la primera vez que se muestra tal ventaja. Y cabe recalcar que el error o tasa de error es demasiado alto para utilizar uno de estos qubits lógicos en un cálculo complejo. Google estima que el rendimiento de los qubits de hardware tendría que mejorar otro 20 por ciento o más para dar una clara ventaja a los qubits lógicos grandes.
En el kit de prensa que lo acompaña, Google sugiere que llegará allí lanzando un único qubit lógico de larga duración, «2025-plus». En ese momento, se enfrentará a los mismos problemas en los que IBM está trabajando actualmente. solo hay una cantidad limitada de qubits de hardware que puede caber en un chip, por lo que una gran cantidad de chips deben conectarse en red en una sola unidad informática. para ser arreglado Google se negó a fijar una fecha para probar las soluciones allí. (IBM dice que probará diferentes enfoques este año y el próximo).
Entonces, para ser claros, una mejora del 0,11 por ciento en la corrección de errores, que requiere aproximadamente la mitad de la CPU de Google para acomodar un qubit, no representa ningún progreso computacional. No estamos más cerca de romper el cifrado que ayer. Pero muestra que ya estamos en un lugar donde nuestros qubits son lo suficientemente buenos como para no empeorar las cosas, y que llegamos mucho antes de que la gente se quedara sin ideas sobre cómo hacer que los qubits de hardware funcionen mejor. Y eso significa que estamos más cerca de donde los obstáculos técnicos que tenemos que superar tienen menos que ver con el hardware qubit.
Naturaleza, 2023. DOI. 10.1038/s41586-022-05434-1 (Sobre los DOI).

Beer ninja. Internet maven. Music buff. Wannabe web evangelist. Analista. Introvertido
